본 글은 현대 컴퓨팅의 발전사를 이해하기 위한 Background Knowledge 입니다. CPU부터 시작해 GPU, NPU, CXL, PIM 등이 왜 등장하였으며, 어떤 역할을 하고 있고, 간단한 개념이 무엇인지 이해하는 것이 목표입니다.
글의 목표를 위하여 각 Computing Unit을 아주 자세히 이야기 하진 않습니다. 추후에 각 주제별로 따로 글을 작성할 예정입니다. 궁금하신 부분 혹은 오류는 댓글로 알려주시기 바랍니다.
Background: Computer Architecture History
컴퓨팅 하드웨어의 발전은 소프트웨어 발전을 빼놓고 이야기할 수 없습니다. 현재 세상을 이끌고 있는 것은 소프트웨어 빅테크 이기 때문에, 하드웨어 아키텍처는 그러한 SW들을 빠르게 처리할 수 있도록 발전하고 있습니다.
2010년대쯤 까지만 하더라도 무어의법칙에 의해 CPU의 발전만으로도 범용적인 SW들을 처리하는데 큰 문제는 없었습니다. 2000년대 중반쯤 싱글코어로 발전하던 CPU는 아래 그래프와 같이 기술적 한계로인해 클럭을 더 이상 높일 수 없었고 (따르는 발열 때문에) 그래서 등장한 것이 '멀티 코어 프로세서' 입니다.

How) CPU는 어떻게 발전하였을까? (최적화를 중심으로)
CPU 성능에 중요한 요소 중 하나는 Memory 성능입니다. CPU는 위 그래프와 같이 성능이 계속 발전하였지만, 그 기간동안 CPU와 비교 했을때 Memory 성능은 거의 발전하지 않은 수준과 같습니다. 여기서 말하는 Memory 성능 이란, Memory에 접근하였을 때 원하는 데이터를 반환 받기 까지의 시간 즉, Latency 입니다.
CPU 성능이 발전하면, 상대적으로 Latency가 높아지는 꼴입니다. 이것을 Memory Bottleneck 이라고 하죠. 그렇담, CPU 성능을 올릴 수 있는 방법 중 하나는 이 Latency를 "Hiding"하는 것이고, 아래와 같은 다양한 기법들이 도입되었습니다. (물리적으로 Latency를 없애는건 불가능 하니까요.)
- Out-of-Order Execution
- Prefetching
- Cache Memory, Non-Blocking Cache
- Multi-threading
- Memory-Level Parallelism
- 등
하지만, 2010년대 들어서 2가지 문제가 생겼습니다. 멀티코어 프로세서가 등장하였지만 CPU의 성능은 더 이상 Linear 하게 증가하지 못하였고, 때문에 계속 떠오르는 새로운 워크로드들을 효율적으로 처리하기가 힘들어 졌습니다.
그래서 등장한 것이 일명 가속기 (Accelerator) 입니다. 가속기란, 범용적인 CPU로 처리하는 것이 아닌 해당 워크로드에 특화된 연산장치를 의미합니다. 해당 워크로드에 특화 되었기 때문에, CPU를 사용하는것보다 훨씬 빠르고 경제적일 것 입니다.
What) 워크로드에 특화되었다는 것이란?
컴퓨팅 관점에서 어떠한 SW워크로드든 덧셈,빼기,곱셉 등의 연산들의 묶음으로 치환됩니다. 예를 들어 어떠한 형태의 AI 모델이 나오든, 현재 트랜스포머 기반의 AI들은 아키텍처 관점에서는 "행렬곱"으로 이루어져 있습니다. 현대 CPU는 행렬곱 연산에 최적화 되어있지 않기때문에, 단순하게는 AI 가속기 라는 것이 "행렬곱"을 잘 처리하는 연산 장치라고도 이해할 수 있습니다.
가속기의 등장으로 인하여, xPU의 시대가 열렸습니다. 그래픽 연산을 담당하던 GPU는 다르게 보면 단순한 연산들을 잘 처리할 수 있는 연산기의 집합체였습니다. 그래서 GPU를 그래픽 연산이 아닌, 범용 연산에 사용하자는 패러다임이 GPGPU (General Purpose Computing on GPU) 입니다. 또한 GPGPU의 핵심은 Core가 CPU처럼 1,2개가 아닌 수백개에 달했기 때문에 "병렬 처리" 패러다임 이었습니다.
여기 또 하나의 문제가 발생합니다. CPU든 GPU든 연산이 빨라지는 것은 좋은 일입니다. 하지만 연산을 하기 위해서는 "데이터"가 필요합니다. 즉 연산 속도에 맞게 데이터를 공급해줄 수 있어야 하죠. 그래서 xPU에 맞추어 "메모리"의 역할도 중요해지는 시대가 되었습니다.
2010년대 중반부터 세상일 이끌어나가는 IT 기술은 단연 "AI" 입니다. 초기 CNN은 다소 Computer-bound 했습니다. CNN 모델의 파라미터를 모두 Memory에 넣을 수 있었고, 연산에 필요한 가중치들은 Memory에서 Cache(SRAM)으로 가져오는데, Cache로 가져온 가중치들의 재사용(Reuse)이 높았기 때문에, 전체 성능 측면에서 연산하는 시간이 메모리 접근하는 것 보다 많은 부분을 차지했습니다. 이러한 형태를 "Compute-Bound" 하다고 합니다. 반대로 전체 시간 중 메모리에 접근하는 비중이 큰 경우를 "Memory-Bound"하다고 합니다.
하지만 트랜스포머 등장 이후, Large-Language-Model (LLM)로의 전환, 나아가 생성형 LLM 이 지배하고 있는 현 시점에서 LLM은 가장 대표적인 "Memory-Bound"한 워크로드입니다. 때문에 가속기와 더불어 "Memory"가 중요해지는 시대가 왔습니다.
LLM 시대에 Memory가 중요한 이유는 다음과 같습니다. (정확히는, LLM Inference)
- Memory Capacity: LLM은 말 그대로 Large 합니다. 아래 그래프와 같이 모델의 사이즈가 점점 커져 가장 High-End 급의 GPU 1개 용량을 벗어나기 시작한게 2019년 입니다. 모델 전체를 Memory에 올리지 못하면, 원하는 데이터가 Memory에 없을 때, SSD/HDD에 접근을 해야 합니다. Disk로의 접근은 성능에 엄청난 악영향을 미칠 것입니다.
- Memory Bandwidth: LLM은 엄청난 메모리 대역폭을 요구합니다. 메모리 용량이 매우 커져 모델을 메모리에 담을 수 있다고 하더라도, 캐시 크기가 제한된 이상, 계속 메모리 접근을 할 것입니다. 메모리 접근이 과도해지면, Core Utilization은 줄어들 수 밖에 없습니다. 데이터가 없으니 연산을 할 수 없는 것이죠. 최근 이슈인 H100, B100 등 Nvidia의 High-End 급 AI 서버용 GPU 에 탑재되는 "HBM"이 여기서 등장합니다. HBM은 High-Bandwidth-Memory로 다양한 메모리 제품 군 중에서 "대역폭"에 집중한 메모리 입니다.

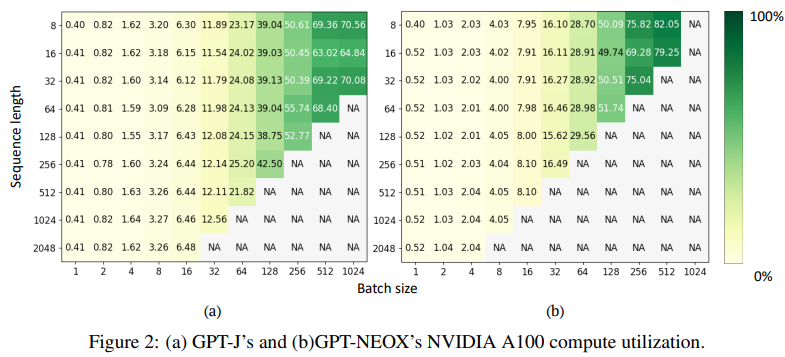
아래 Figure는 위 2가지 문제를 잘 종합해 보여줍니다.
좋은 LLM Service Product를 제공하기 위해서는 Sequence Length를 높여야 합니다. 아래 그래프에서는 S.Length를 높이면 제공 가능한 최대 Batch size가 줄어드는 모습을 보여줍니다. 그리고 박스안에 적힌 숫자가 굉장히 작아지죠. 이 숫자는 Cumpute Utilization을 의미합니다. 예를 들어, S.Length가 1024일 때, 최대 Batch는 32와 8로, 각각 12%, 4% 수준의 처참한 GPU 활용률을 보여줍니다. 이는 메모리 대역폭이 부족한 결과입니다.
GPU 활용률을 높이기 위해서는 Batch Size를 키워야 하는데, 이 경우 Memory Capacity 제약으로 인해 S.Length가 낮아지며, 그렇지 않을 경우, NA로 표기된 부분 OOM 즉, 메모리가 부족해 프로세스가 종료됩니다.
How to Solve Problems?
대 LLM의 시대. LLM 추론 서비스를 잘 제공하기 위해선 다양한 방법이 존재합니다. 크게 SW와 HW적인 솔루션으로 나눌 수 있습니다. 글을 작성하고 있는 시점을 기준으로, 아직 시장에 정해진 정답은 존재하지 않습니다. 여러 컴퍼니들은 자신만의 솔루션을 구축하고 있으며 시장의 파이를 먹기 위해 고군분투 경쟁하고 있는 시대죠. 누가 살아남을지는 알 수 없습니다.
크게크게 몇 가지 주요 솔루션을 살펴보도록 하겠습니다.
Software Solution
대표적인 몇 가지 방법을 소개하도록 하겠습니다. 더욱 자세한 내용은 링크 참고바랍니다.
https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
Stacking transformer layers to create large models results in better accuracies, few-shot learning capabilities, and even near-human emergent abilities on a wide range of language tasks.
developer.nvidia.com
아래 Notion 또한 정리가 잘 되어 있으니 읽어보시면 좋습니다.
LLM Inference - HW/SW Optimizations | Notion
Linkedin의 원저자(Sharada Yeluri)의 허락을 받아 원문을 번역 및 검수중입니다.
tulip-phalange-a1e.notion.site
1. KV(Ker-Value) Caching
LLM의 주요 연산인 Attention 연산은 Query-Key-Value를 Generation하고 각각의 Dot-Product로 이루어져 있으며 토큰 생성과정에서 Key와 Value는 같은 값이 재생산됩니다. 따라서, KV를 재생산 하는 것이 아닌, 한 번 만들어진 값을 재사용 하자는 것이 KV Caching 입니다.
2. Parallelism
이전 그래프를 통해 LLM 모델을 하나의 GPU Memroy에 넣을 수 없음을 알았습니다. 그래서 등장한 것이 Multi-GPU System (Distributed System) 입니다. 여러대의 GPU를 이용해 LLM Inference를 처리하는 것이죠. 이때 생길 수 있는 문제는, 그럼 어떻게 GPU 여러 개를 잘 사용할까? 입니다.
여기서 등장하는 개념이 Parallelism이며, 기존 병렬처리 관점이 아닌, AI 모델을 어떻게 여러 GPU에 쪼개서 병렬처리를 할까의 개념에 가깝습니다. 분산하는 방법에 따라 Model Prallelism, Data Parallelism, Tensor Parallelism 등의 다양한 방식이 존재합니다.
GPU Fabrics for GenAI Workloads | Notion
Linkedin의 원저자(Sharada Yeluri)의 허락을 받아 원문을 번역 및 검수중입니다.
tulip-phalange-a1e.notion.site
3. Attention
Attention, Multi-Head Attention (MHA) 은 "Attention Is All You Need" 논문을 통해 세상에 공개되었고, 그 이후로 Attention 연산을 최적화 하는 연구 또한 많이 진행되었습니다.
Attention 방법은 유지한 채 구조를 바꾼것으로 유명한 방법은 아래와 같습니다.
- Multi-Query Attention (MQA) from [19`arxiv] Fast Transformer Decoding: One Write-Head is All You Need
- Grouped-Query Attention (GQA) from [23`EMNLP] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Attention 을 수정하는 접근으로 유명한 것들은 다음과 같습니다.
- Flash Attention from [22`NeurIPS] Flash Attention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- PagedAttention from [23`SOSP] Efficient Management for Large Language Model Serving with PagedAttention
제가 AI Inference의 SW Optimization을 연구하고 있는건 아니어서, 위 내용들을 직접 소개할 만큼 지식을 갖고 있지 못합니다. 관심있는 분들은 위 논문 혹은 아티클 찾아보시면 좋을 듯 합니다.
4. Quantization (양자화)
양자화는 모델의 사이즈를 줄이는 방법입니다. GPT3가 175B의 파라미터를 가지고 있다고 하는데, 각각이 FP16으로 표현될 경우, 16bit=2Byte 이므로 전체 크기는 350GB라고 대강 유추할 수 있으며 (정확하진 않습니다) 이는 80GB 메모리를 가진 H100 4대가 필요한 양입니다.
반면, FP16을 INT8로 양자화하는 방법을 통해 절반 사이즈로 줄일 수 있습니다. 이 경우 모델 사이즈는 175GB가 되며, 단순히 사이즈를 줄이는 것을 넘어, 사이즈가 줄면 메모리 접근이 줄고 연산 활용률을 높일 수 있습니다. 또, 필요한 GPU 개수가 줄어 경제적인 역할도 겸하죠.
양자화는 PTQ (Post-Training Quantization), QAT(Quantization-Aware Training) 등 다양한 방법이 연구되고 있습니다.
관심있으신 분들은 기본적으로 PTQ, QAT를 공부하신 후에 논문을 읽어보시면 좋습니다. -> https://tulip-phalange-a1e.notion.site/a947f0efb8eb4813a533b0d957134f6d
- [21`arxiv] A White Paper on Neural Network Quantization -> 리뷰 논문입니다.
- [23`ICLR] GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- MIT Song Han 교수님의 논문들
- 양자화 뿐만 아니라, AI 가속분야 세계적 대가입니다.
양자화에 관한 비주얼 가이드 | Notion
원저자(Maarten Grootendorst)의 허락을 받아 원문을 번역 및 검수중입니다.
tulip-phalange-a1e.notion.site
5. vLLM
마지막으로, 가장 핫한 vLLM 입니다. vLLM은 소프트웨어 최적화를 통해 LLM 추론 서비스를 무려 최대 "24배" 성능을 높였습니다. 그리고, vLLM은 앞서 말한 PagedAttention을 기반으로 하고 있습니다. 자세한 내용은 링크 참고 바랍니다.
https://tech.scatterlab.co.kr/vllm-implementation-details/
최대 24배 빠른 vLLM의 비밀 파헤치기
최대 24배의 성능을 보인 vLLM, 코드 레벨까지 분석해보자!
tech.scatterlab.co.kr
이 외에도 MoE, LoRA 등 LLM 성능을 최적화 하기 위한 많은 방법들이 도입되고 있습니다. 이쪽 논문들을 계속 Follow-Up 하고 있는건 아니라서 어떤 솔루션들이 나왔다 정도만 알고있지 자세한 내용을 직접 전해주지 못해 아쉽네요. 계속 공부하면서 새로운 소식 있으면 글을 쓰도록 하겠습니다.
Hardware Solution
LLM 가속을 위한 Hardware Solution은 그야말로 춘추 전국 시대나 다름 없습니다. 각 컴퍼니 마다 다른 방식으로 하드웨어 솔루션을 제시하고 있으며 어떤 컴퍼니가 살아남을 것인지 관전하는 포인트도 있겠습니다.
하지만, 또 하나의 새로운 관점은 Software Solution vs. Hardware Solution 입니다. 가속기의 선두 주자인 Google TPU는 2016년 v1에서 시작해 현재 v5까지 개발하였고, 2023년 ISCA에서 TPU v4 논문에서 말하길, Nvidia A100 대비 1.2-1.7배의 성능을 달성했다고 했습니다. 발매 후 7년, 이전 개발기간 까지 포함하면 대략 10년의 시간인데, 가속기가 GPU 대비 2배의 성능도 못냈습니다. 반면 앞서 말한 vLLM 은 Software Optimization으로만 "24배" 향상시켰죠.
Nvidia 또한 칩을 발매하고나서 계속되는 Software Optimization으로 성능을 계속 향상시킵니다. 이렇게 되면 가속기를 만드는게 GPU를 어떤 방식으로 이겨야할지... 저는 가늠이 잘 되질 않긴 합니다. 재밌는 관전 요소라고 할 수 있죠.
1. Nvidia GPU
Nvidia GPU에 대항하기 위해 NPU (Neural Processing Unit)이 등장하였지만, GPU만의 장점도 무시할 수 없습니다.
GPU의 최대 장점이자 단점은 "General Purpose" 라는 것입니다. 현재 NPU 들은 Transformer 가속에 집중하고 있습니다. Transformer는 행렬곱으로 이루어져 있으며, 행렬곱에 한해 NPU들은 GPU보다 더 나은 전성비를 보이고 있지만, 만약 새로운 AI 알고리즘이 등장하고, 그 기반이 행렬곱이 아닐 경우엔 NPU에게는 다소 안타까운 상황이 펼쳐질 것입니다.
Nvidia 또한 바보가 아니겠죠. Nvidia는 어떠한 알고리즘이라도 돌릴 수 있는 General Purpose를 바탕으로 트랜스포머 연산에 특화된 Transformer Engine, GPU간의 통신을 위한 NVLink, 그리고 CUDA를 기반으로 강력한 소프트웨어 툴을 넘어 GPU에서 AI Inference Software 최적화를 위한 TensorRT 등 다양한 무기를 보유하고 있습니다.
지난 40년간 CPU 시장을 점유했던 Intel과 같이, 하드웨어는 한 번 점유하면 왕좌가 쉽게 바뀌지 않습니다. NPU가 등장하였더라도, 앞으로의 Nvidia의 성장세를 무시할 수는 없는 상황입니다.
2. NPU (Nerual Processing Unit)
앞서 Nvidia의 장점을 언급했지만, Nvidia의 단점은 괴랄한 성능을 위한 Power와 가격에 있습니다. Nvidia 칩의 구매자인 빅테크들 (Meta, Google, Tesla 등)은 저마다의 100MW 이상급의 데이터 센터를 구축하고 있으며, 100MW는 소규모 도시 이상의 대형 산업단지가 쓸 수 있는 전기량과 맞먹습니다. 나아가 앞으로는 GW (기가 와트) 급의 데이터 센터가 건설될 예정이라고 하니, 엄청난 전력 = 돈이죠.
여기서 말하는 칩은 우리에게 익숙한 소비자 용인 4080, 4090칩이 아닌 서버용 초 하이엔드 GPU인 H100, B100등을 일컫습니다. 그리고 Nvidia는 이러한 칩을 1개 단위가 아닌 묶음으로 판매합니다. 이를 DGX라고 하며, 칩 하나에 몇 천만원인데 묶음 단위로 파니 단가는 수십 수백억 단위가 될 것입니다. 이러한 가격과 전기세까지 고려하면 빅테크가 아니면 쉽게 넘볼 수 없는 영역이 되어버린 것이죠.
때문에 이 포인트에서 NPU가 등장하는 것입니다. NPU가 GPU와 비벼볼만한 부분이 1) 전성비, 2) 저전력 3) 가격 인것이죠.
Transformer 가속을 위한 NPU는 Transformer 가속을 위한 부분 이외에 불필요한 부분을 모두 덜어낸 연산 장치입니다. GPU처럼 그래픽 처리 장치를 넣을 필요가 없죠. 그렇게 늘어난 Area는 다시 연산 장치 혹은 SRAM으로 채울 수 있습니다. NPU가 주로 타겟하는것은 전성비 (Performance/Watt) 로, GPU 대비 먹는 전기가 적으며 더 높은 성능을 낸다는 이야기 입니다. 당연히 가격도 GPU에 비해 저렴하겠죠.
하지만 NPU의 문제는 2가지가 존재합니다. 첫째, 앞으로도 행렬곱 기반의 알고리즘이 유지될 것인가? 둘째, NPU를 지원하는 소프트웨어가 얼마나 Programmablity가 높은가? 여기서 GPU와 대립하는 것이죠. 어떠한 알고리즘도 돌릴 수 있도록 설계된 GPU Architecture와 CUDA 기반의 오래 검증된 Software을 가진 GPU와 말이죠.
또, 재미있는 점은 각 NPU 회사마다 접근하는 아키텍처가 다르다는 겁니다. Cerebras 는 Wafer-scale로 엄청나게 거대한 장치를 만들고 있고, 칩 설계 전설 짐 켈러 (Jim Keller) 의 Tentorrent는 RISC-V기반의 코어로 이루어진 약간 GPU스러운 NPU를 만들었습니다. 또한 한국의 Rebellions 나 Furiosa도 자신들만의 칩을 만들어내고 있죠. 이 밖에도 세계적으로 엄청난 수의 NPU 스타트업들이 우후죽순으로 생겨나고 있습니다. 각 회사만의 NPU들을 정리해 글을 쓰는 것도 재밌을 것 같네요.
3. Memory Capacity Solution: Compute eXpress Link (CXL)
이젠, 연산기가 아닌 Memory 입니다. 제 전공 분야(!) 입니다. Memory Solution은 2가지 접근법이 존재합니다. 1) Capacity 와 2) Bandwidth 입니다. Capacity를 해결할 것으로 유망한 기술은 Compute eXpress Link (CXL) 기반의 메모리 시스템이 있고, Bandwidth 를 위해서는 Processing-in-Memory (PIM) 혹은 Near-Data-Processing (NDP) 가 있습니다. 하나씩 알아보죠.
CPU는 싱글에서 멀티 코어로, 나아가 멀티 소켓에서는 칩간 통신이 필요했고, 서버 단으로 가서는 네트워크를 타고 서버간의 통신이 필요하게 되었습니다. 대용량 데이터를 디스크 등 I/O 장치에서 읽을 때는 CPU가 직접 읽는 것이 아닌 DMA (Direct-Memory-Access) 하드웨어를 사용합니다. 서버간 데이터 전송이 필요할 때는 R-DMA (Remote-DMA) 기술을 사용해왔죠. 문제는 이 RDMA는 기본적으로 하드웨어가 아닌 소프트웨어 기반의 솔루션이라 불필요한 소프트웨어 오버헤드가 크다는 것입니다. 지금처럼 데이터 통신이 많아진 시점에서는 Bottleneck이 된 것이죠.
그래서 등장한 것이 CXL 입니다. CXL은 RDMA대비 고대역폭 및 저 지연시간을 제공하는 PCI-e를 기반으로 만들어진 프로토콜 입니다. CXL을 사용하기 위해서는 CPU의 Memory Controller와 CXL을 지원하는 CXL/PCI-e Port가 따로 필요하죠. 그런데, 지금까지 이야기하는 것은 Capacity Solution과 별반 상관없어 보입니다. 어떻게 이것이 문제를 해결하는 솔루션인걸까요?
CXL은 3가지 프로토콜 CXL.io, CXL.cache, CXL.mem 의 조합을 통해 3가지 디바이스를 지원합니다. 각각 Type1, Type2, Type3 라 합니다.
- CXL.io: PCIe 프로토콜 지원
- CXL.cache: 가속기 디바스이가 호스트 CPU 접근 가능 및 캐시 일관성 지원
- CXL.mem: 호스트 CPU가 Memory Exanpder에 접근 가능
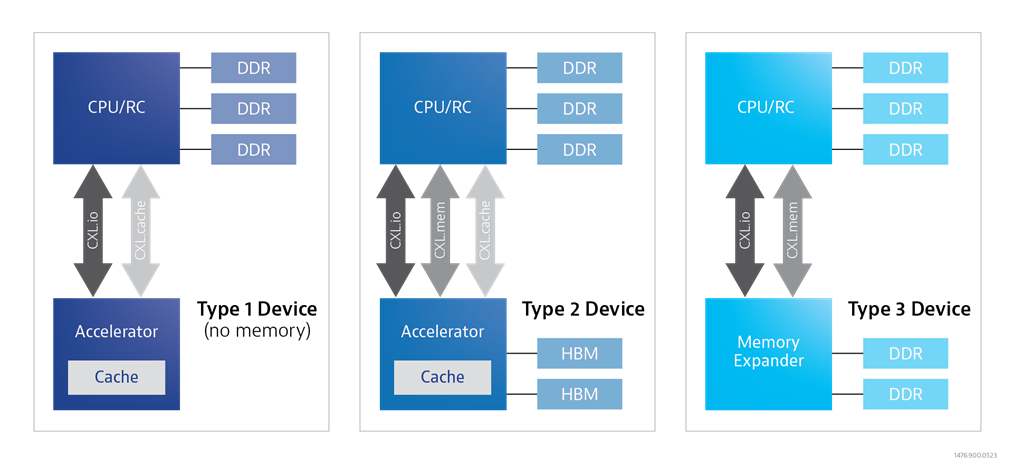
Type 3 Device는, CPU Host가 CXL을 통해 Memory Pool에 접근할 수 있도록합니다. 기존 컴퓨팅에서는 메모리를 추가하기 위해서 다양한 제약이 존재했습니다. 메인보드에 메모리 슬롯 개수 제약이 있으며, CPU가 지원하는 메모리 채널 수에 따라 대역폭이 제한되고, 또한 메모리 타입에 따라 CPU가 지원하는 종류에 한계가 있었습니다.
하지만 Type 3 Device에 CXL로 접근할 때에는 Local Memory System과는 독립적인 Remote Memory System 이기 때문에 CPU와 상관없이 Type 3 Device 내부 메모리를 자유롭게 구성할 수 있는 장점이 있습니다. 즉, 쉽게 Host에게 거대한 메모리 용량을 제공해 줄 수 있게 된 것이죠. Type 3 Device 용량은 현재 개발중인 제품기준 128GB/256GB/512GB 등의 제품이 있으며 근 미래엔 TB단위의 Memory Expander 솔루션이 제공될 것 입니다.
이렇게 메모리 용량을 획기적으로 늘려줄 수 있는 솔루션인 CXL은 "대역폭 확장" 솔루션이기도 합니다. PCIe 대역폭으로 연결된 CXL 내부 대역폭을 시스템 전체 대역폭으로 사용할 수 있는 것이죠. 즉 기존에 메모리 용량 및 대역폭이 부족했던 시스템에서 CXL Memory를 사용할 경우 2마리 토끼를 잡을 수 있는 것...이긴 한데 여긴 아직 해결해야할 문제가 있습니다. 이 글에선 길어질 것 같으니 다음에 CXL만 따로 글을 쓰도록 하겠습니다.
CXL 이야기가 더욱 궁금하신 분들은 다음의 논문 읽독을 추천합니다.
- [23`arixv] An Introduction to the Compute Express Link (CXL) Interconnect
- [23`MICRO] Demystifying CXL Memory with Genuine CXL-Ready Systems and Devices
- [24`IEEE Micro] The Breakthrough Memory Solutions for Improved Performance on LLM Inference
4. Processing-in-Memory (with Near-Data-Processing)
사실 PIM과 NDP는 동일한 개념의 아키텍처는 아닙니다. 우선, 이 기술들의 등장 배경은 다음과 같습니다. 워크로드들이 더욱 많은 데이터를 사용하게 되고 "데이터를 이동"시키는데 엄청난 에너지가 들게 되었습니다. 아래 그림과 같이 Google Workloads 를 활용하는데 있어서 시스템 에너지의 62.7%가 단지 "데이터 이동"에 쓰입니다. 연산도 아니구요. 엄청난 소비죠.

자연스럽게 등장하는 아이디어는 "데이터를 이동시키지 않고 연산하는 방법"이고 그것은 아키텍처적으로 "연산기를 메모리에 가깝게 배치" 하자는 아이디어가 됩니다. 여기까지는 궤를 같이하지만, PIM와 NDP의 차이는 "연산기의 위치"에 있습니다. PIM은 연산기를 메모리 뱅크(혹은 주변)에 배치 시켜 데이터 이동을 거의 최소화하는 것이라면, NDP는 메모리 내부(뱅크 밖) 및 주변에 연산기를 배치시키는 방법입니다.
위치로 인한 차이는 "대역폭"이라고 볼 수 있습니다. 일반적으로 메모리 채널 대역폭 보다 메모리 내부 대역폭이 크며, PIM/NDP를 사용할 경우 메모리 내부 대역폭을 사용해 더 많은 대역폭을 사용할 수 있는 개념입니다. NDP의 경우, 메모리 밖에 연산기가 위치하게 되면 메모리 내부 대역폭을 쓰는건 아니겠죠.
Memory-Bound한 LLM Inference를 PIM으로 해결하는 많은 연구들이 이루어져 왔으며, Samsung과 Hynix에서는 각각 HBM-PIM/AiM 이라는 Product를 내놓았습니다. HBM-PIM은 실제로 AMD의 서버용 GPU MI100 가속기에 탑재되기도 했습니다.
PIM의 장점은 "메모리 내부 대역폭"을 활용해 메모리 접근 시간과 에너지를 아낄 수 있다는 데에 있습니다. 시간이 세이브된 만큼 전체적인 연산 시간도 대폭 줄어드는 효과 또한 있습니다.
하지만, PIM도 모든 문제를 해결할 수 있는 솔루션은 아니며 단점 또한 많이 갖고있습니다. 이에 대해서는 PIM 글을 별도로 분리해 자세히 정리하도록 하겠습니다.
추천 논문은 다음과 같습니다.
- [20`MICRO] Newton: A DRAM-maker’s Accelerator-in-Memory (AiM) Architecture for Machine Learning (hynix)
- [20`TC] MViD: Sparse Matrix-Vector Multiplication in Mobile DRAM for Accelerating Recurrent Neural Networks
- [21`ISCA] Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology (samsung)
- [24`ASPLOS] IANUS: Integrated Accelerator based on NPU-PIM Unified Memory System
- [24`ASPLOS] AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference
여기까지 AI Inference를 중심으로 현대 CPU에서부터 GPU, NPU, CXL, PIM 에 관하여 알아보았습니다.
제가 연구하고 있는 분야는 CXL, PIM이여서 여기에 쓰인 내용보다 더 많은 내용을 작성했으나 난이도나 글의 취지를 고려해 대부분은 다음에 따로 정리하는것으로 했습니다. 그 밖에도 각 회사들의 NPU 개발 방법을 비교해보는 것도 재밌을 것 같아요.
궁금하신 부분은 댓글 주시면 감사하겠습니다.
'Computer Architecture > Computer Architecture' 카테고리의 다른 글
| 컴퓨터 아키텍처(구조)를 어떻게 공부할 것인가? (1) | 2024.02.08 |
|---|---|
| DRAM 메모리 시스템 구조와 개요 (0) | 2023.09.08 |
| Computer Architecture - Top tier paper lists (0) | 2023.09.08 |